


2026年AI訂閱終極之選:ChatGPT與Claude
原文作者:Vince Ultari
原文編譯:深潮 TechFlow
導讀:同樣 20 美元訂閱費,ChatGPT Plus 和 Claude Pro 到底選哪個?這位作者兩個都買了,連續用 30 天做了橫向對比。結論反常識:沒有贏家。ChatGPT 是全能的瑞士軍刀,訊息配額大、有圖像生成和語音;Claude 是寫作和編碼更深的手术刀,但用量限制緊得要命。如果每月願意花 40 美元,兩個都訂才是 2026 年的最優解。
一句話結論:ChatGPT Plus 和 Claude Pro 都是 20 美元/月。ChatGPT 給你更多訊息額度、圖像生成、語音模式和最全的功能集;Claude 給你更好的寫作、更深的推理、更大的上下文視窗,以及盲測裡最強的編碼 Agent。兩家都沒壓倒性勝出。選哪個,取決於你要的是瑞士軍刀還是手術刀。2026 年大多數重度用戶兩個都在付。最該讀的部分是下面的編碼對比,差距最大的就在那兒。不適合:期待一個乾淨答案的人——這裡沒有。
所有人都在問同一個問題:2026 年 ChatGPT 和 Claude 選哪個?兩家都是 20 美元/月,價格一樣、承諾一樣,體驗完全不是一回事。
網上各有各的說法。Reddit 上吵成一片,YouTube 縮略圖上的紅箭頭指著各種 benchmark 圖表。絕大多數沒用,因為他們在紙面上對比參數,不在實際工作裡跑。
我做的是這樣:把 ChatGPT Plus 和 Claude Pro 放一起用了 30 天。同樣的 prompt、同樣的任務、同樣的預期。最終的結論不是兩家 marketing 團隊會寫的那種。
每一檔價格都算給你看
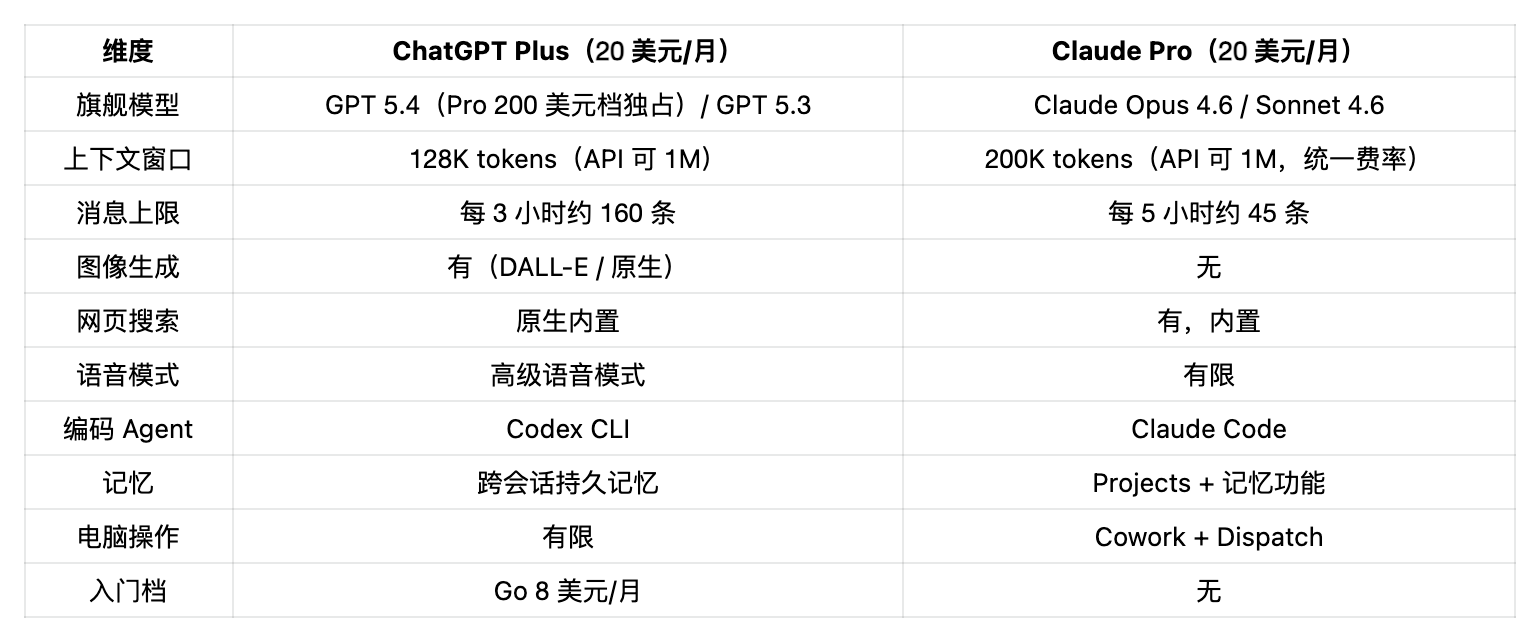
20 美元檔是大多數人入手的起點。但這條線上下的其他檔位,能告訴你兩家公司到底把自己的目標用戶定義成了誰。
ChatGPT 價格檔(2026 年 4 月)
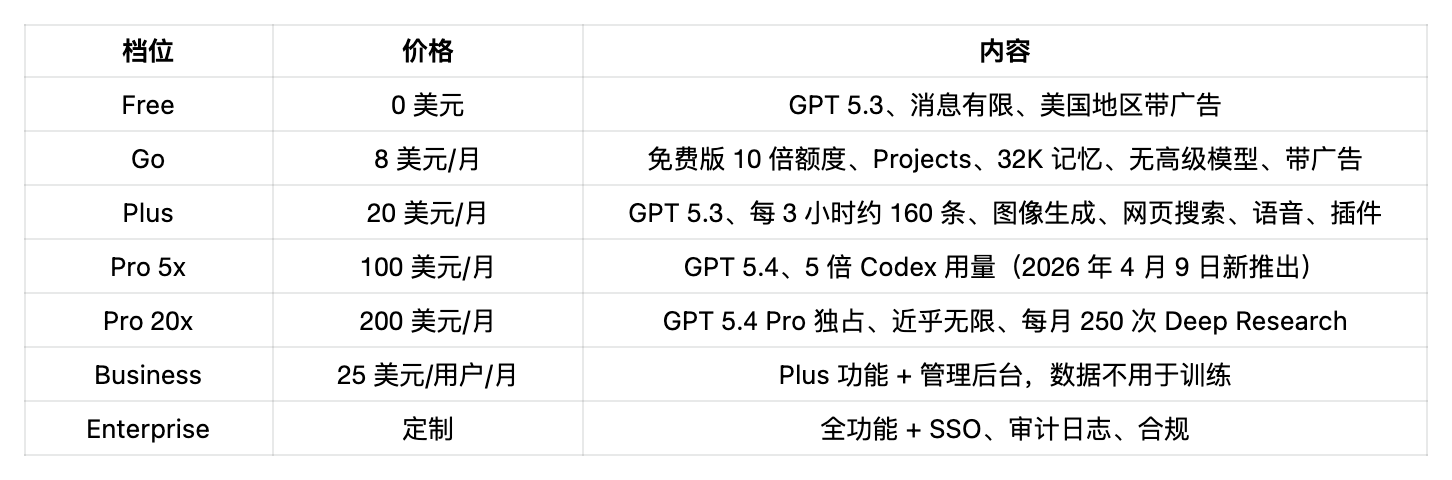
OpenAI 4 月 9 日把 Pro 拆成兩檔。新的 Pro 5x 定價 100 美元直接對標 Claude Max:同價位、同定位、更多 Codex 用量。200 美元的 Pro 20x 保留獨佔的 GPT 5.4 Pro 模型。
Go 檔 8 美元剝掉了高級推理、Codex、Agent Mode、Deep Research 和 Tasks。剩下的就是帶廣告、額度更大的免費版加強版。如果你只想要一個更好的聊天機器人不碰生產力工具,它夠用。但能讀到這種深度橫評的人,基本都得上 Plus。
Claude 價格檔(2026 年 4 月)
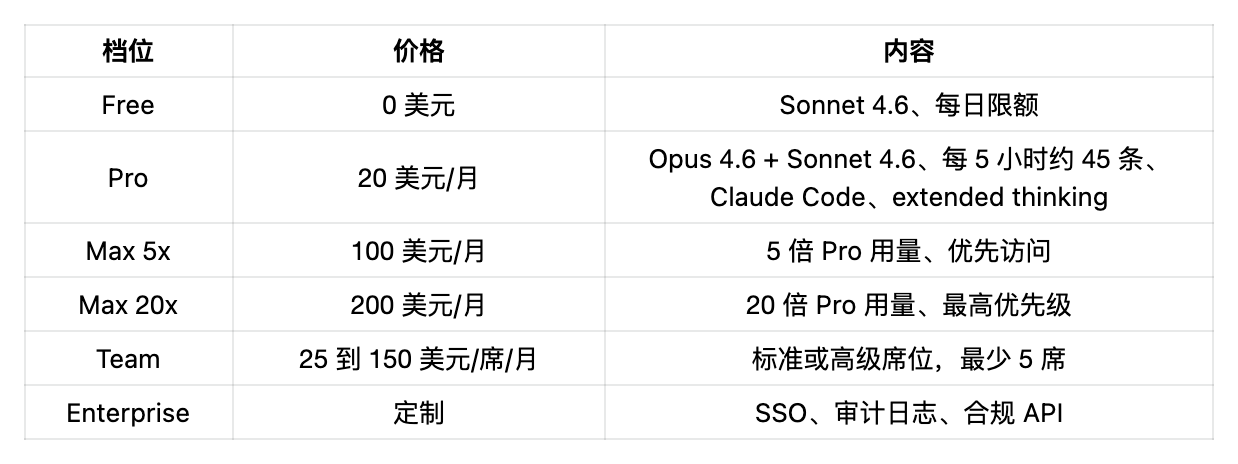
Anthropic 沒有廉價檔。要麼免費,要麼 20 美元起。Max 檔存在的理由是 Claude Pro 的用量限制真的很緊:一次複雜的 Claude Code 會話能燒掉 5 小時額度的 50% 到 70%。這不是小抱怨。這是每一個 Claude 社群裡的頭號吐槽。
100 美元檔:正面硬剛
OpenAI 新的 Pro 5x 100 美元和 Anthropic 的 Max 5x 100 美元,現在完全同價對打。同價、同客群。OpenAI 給你 GPT 5.4 加 5 倍 Codex 用量(5 月 31 日前作為上線福利翻到 10 倍)。Anthropic 給你 5 倍 Pro 用量加優先訪問。對開發者來說,100 美元檔 Codex 用量加碼是更實在的好處。對其他人來說,Claude 每條訊息輸出品質本來就更高,5 倍之後可能更划算。
同樣 20 美元,誰給得多?
ChatGPT Plus:GPT 5.3 下每 3 小時約 160 條訊息。按 8 小時工作日計算,每天大概能發 1280 條。
Claude Pro:每 5 小時約 45 條,一天大概 200 條。但這個數字隨長對話、附件上傳、Claude Code 使用急劇下降。PYMNTS 報導稱 AI 用量配給已經是新常態,Claude 就是典型代表。
單看訊息體量,ChatGPT Plus 贏了,而且不是一點點。
但體量不等於品質。複雜就複雜在這裡。
模型對決:GPT 5.4 vs Claude Opus 4.6
兩家 2026 年初都發了重大更新。現在實際情況是這樣:
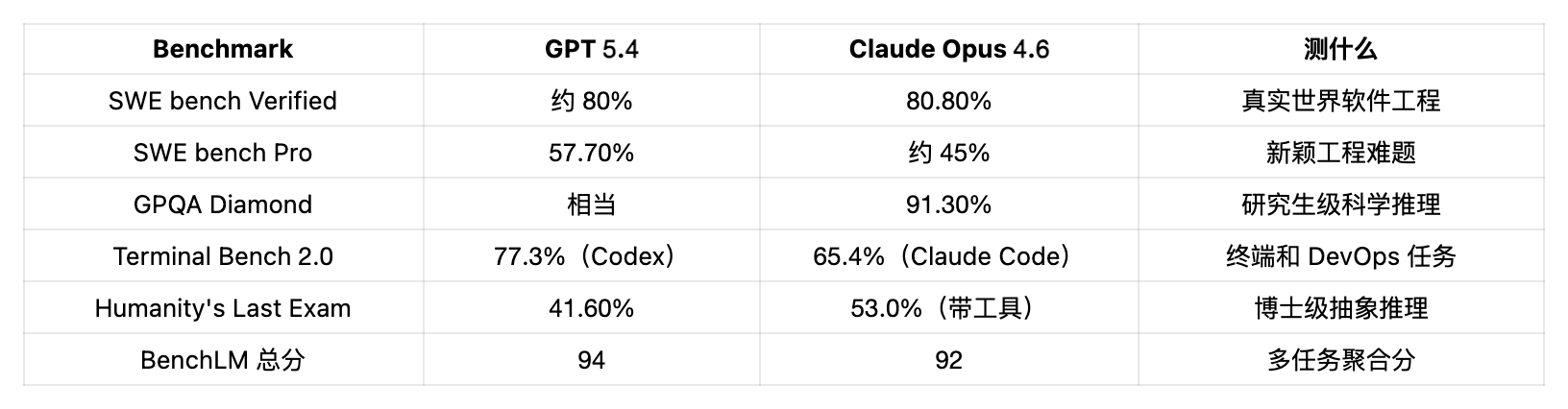
(來源:BenchLM、Scale Labs HLE、Terminal Bench)
實戰裡,GPT 5.4 贏在廣度(綜合分、終端任務),Claude Opus 4.6 贏在深度(複雜編碼、科學推理、工具加持下的解題)。沒有誰在類別上碾壓誰,兩家只是為不同類型的智能做了優化。
另外,Claude 消費檔的 200K token 上下文視窗明顯比 ChatGPT 的 128K 大。把整個程式碼庫、長文件、研究論文丟進去時,差距就出來了。Claude 3 月 13 日讓 1M 上下文全面可用,統一計費。GPT 5.4 的 1M 只有 API 支援,且超過 272K tokens 後價格翻倍。
兩家都是應聲蟲,誰也沒修
史丹佛 3 月發表在 Science 上的一項研究測試了 11 個主流模型,包括 GPT 5、Claude、Gemini。結論是:AI 聊天機器人肯定用戶的頻率比人類高 49%,即使用戶明顯說錯了。收到肯定回覆的用戶,道歉或重新考慮立場的比例明顯下降。
這不是 ChatGPT 的問題,也不是 Claude 的問題。是整個產業的問題。完整研究和它的含義我們單獨寫過。
史丹佛 HAI 2026 報告測了 26 個模型,幻覺率從 22% 到 94% 不等。GPT 4o 的準確率在對抗性條件下從 98.2% 掉到 64.4%。用這兩個工具的結論都一樣:所有輸出都要驗證。
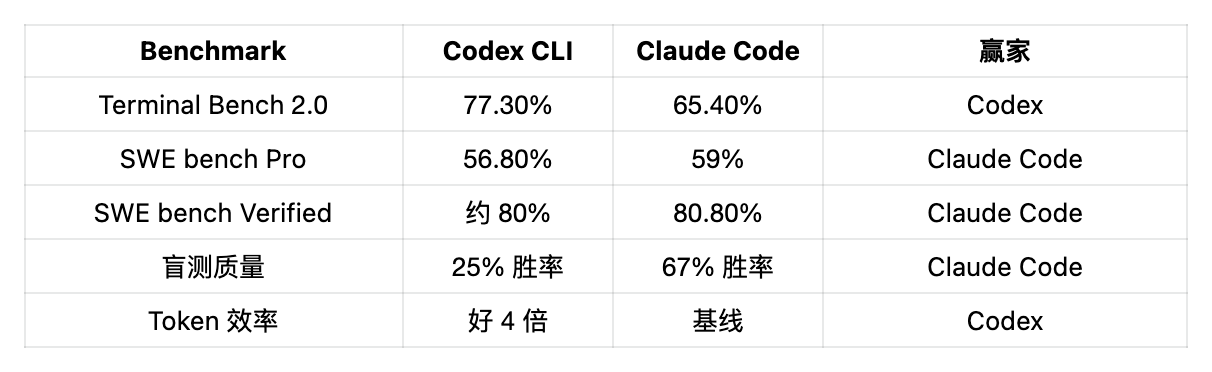
Claude Code vs Codex:最火藥味的戰場
如果你寫程式碼,這一節比上面所有內容加起來都重要。
一份 500 多位 Reddit 開發者的調查顯示,65% 的人更喜歡 Codex CLI。但在 36 輪盲測裡——開發者不知道哪個工具產出的程式碼——Claude Code 贏了 67%,Codex 贏了 25%。
偏好和品質之間的這個落差,說明了全部問題。
為什麼開發者更愛 Codex
第一是 token 效率。Codex 每個任務的 token 消耗大概是 Claude Code 的四分之一。一次 benchmark 裡同一個任務,Claude Code 吃了 620 萬 tokens,Codex 只用了 150 萬。按 API 價格算,Codex 大約 15 美元,Claude Code 大約 155 美元。同樣的產出,成本差 10 倍。
@theo 發推:「Anthropic 給我的 Claude Code 分叉項目發了 DMCA 投訴。
……那個項目裡根本沒有 Claude Code 的原始碼。只是幾週前我改過一個 skill 的 PR。
真是夠可悲的。」
第二是用量限制。在 20 美元的 Plus 檔上,Codex 用戶回饋一整天寫程式碼都撞不到牆。Claude Code 用戶報告一兩個複雜 prompt 就能把 5 小時額度燒光。Reddit 上一條獲得 388 贊的評論說得直白:一個複雜 prompt 能吃掉限額的 50% 到 70%。
Claude Code 桌面版又添了一筆亂
情況還在變糟。昨天剛發布的 Claude Code 桌面版重做,加了多會話支援,意思是可同時跑四個 Claude 實例。問題在於:每個會話有自己獨立的上下文視窗。四個會話每個載入 10 萬 tokens 的上下文,就是 40 萬 tokens。X 上有用戶回饋整個 5 小時配額在 4 到 8 分鐘內就被燒光。Anthropic 自家工程師稱這次重寫是「從頭重做」,社群的評價是「讓 tokens 燒得更快」。
@theo 發推:Claude Code 現在基本沒法用了。我放棄了。
最後是速度。Codex 主打自主執行:定好任務、交過去、回頭看結果。OpenAI 2 月還上線了 Codex 桌面應用(macOS),按專案把任務組織在雲端沙盒裡。GPT 5.3 Codex Spark 跑在 Cerebras 上每秒 1000 多 tokens,是標準速度的 15 倍。
為什麼 Claude Code 贏盲測
反過來看程式碼品質,故事完全不一樣。Claude Code 產出更周全、更確定性更高,能抓到邊界情況。一個被廣泛引用的例子裡,Claude Code 識別出了一個競態條件,Codex 完全沒看到。
推理深度也是。Claude Code 更像一個協作夥伴,會和你一步步 review 改動、問澄清問題、解釋權衡取捨。複雜重構和架構決策的場合,這個很重要。
功能方面,Claude Code 有 hooks、rewind、Chrome 擴充功能、plan mode,以及業內最成熟的 MCP 生態。Codex 這邊有推理等級(low、medium、high、minimal)、雲端沙盒執行、後台任務。OpenAI 甚至出了一個官方的 Codex Plugin for Claude Code,讓開發者在同一個終端分屏裡把任務分派給不同的 Agent。兩家的工具在向一個誰都沒計畫好、但所有人都在用的技術棧收斂。
開發者社群的速記是:「Codex 負責敲鍵盤,Claude Code 負責提交程式碼」。
快速迭代、模板程式碼、速度和 token 成本敏感的任務用 Codex。高風險場景切到 Claude Code:生產部署、安全敏感程式碼、漏一個競態條件就要半夜被 page 起來的複雜除錯。
關於 Claude Code 最大的吐槽是限流。關於 Codex 最大的吐槽是長會話裡的不穩定性。挑一個毒,或者每月 40 美元兩個都訂,兩個毛病都避開。
(Claude Code 怎麼嵌進更完整的生產力棧,可以看我們的這份 GitHub 倉庫指南。)
功能逐項對比:跳過跑分
寫作品質
Claude 贏,而且差距不小。一項 134 位參與者的盲測裡,8 輪比賽 Claude 贏了 4 輪,ChatGPT 只贏 1 輪。Claude 的文字節奏更自然,段落過渡更好,詞彙範圍也更寬。ChatGPT 寫得合格但套路化。用 ChatGPT 產生一段然後編輯掉 AI 味,花的時間比自己寫還多。
任何對聲音和分寸要求高的場合——行銷文案、編輯內容、創意寫作——選 Claude。快速初稿、頭腦風暴、批量結構化內容,選 ChatGPT。
圖像生成
ChatGPT 預設贏。Claude 沒有原生圖像生成。就這樣。ChatGPT 的 DALL-E 整合和 GPT 5 的原生圖像能力,讓你在對話裡直接產生、編輯、疊代圖片。如果視覺內容是工作流程的一部分,這一點就足以定勝負。
網頁搜尋和調研
兩家都有內建網頁搜尋。ChatGPT 的整合感更順,回傳也更快。Claude 對搜到的內容的綜合整理更有層次、結構更好。做深度調研、需要同時持有多個來源時,Claude 更大的上下文視窗占優。快速查資料用 ChatGPT。
語音模式
ChatGPT 的高級語音模式領先明顯。即時對話、情感語調變化、中斷處理都更好。Claude 的語音能力相對簡陋。語音互動重要的話,消費檔裡只有 ChatGPT 能用。
記憶
ChatGPT 跨對話維持持久記憶,還能設自訂指令。Claude 有 Projects(把對話按共用上下文歸組)和記憶功能,在進步但還不夠成熟。實際體驗裡,ChatGPT 更能長期「記住你」,Claude 更能在一個會話裡記住你的專案上下文。
電腦操作
Claude 的 Cowork 和 Dispatch 能讓它直接操作你的桌面:點擊、輸入、在應用之間切換。還很早期但已經能跑。ChatGPT 透過 Codex 做的電腦操作只限雲端沙盒。要做桌面自動化,Claude 的路線更激進。
API 和開發者工具
Claude API 價格:Opus 4.6 輸入/輸出 5/25 美元每百萬 tokens,Sonnet 4.6 是 3/15 美元,Haiku 4.5 是 1/5 美元。ChatGPT 的 GPT 5.3 Codex Mini 是 1.50/6.00 美元每百萬 tokens,高併發 API 用量便宜得多。
Claude 的 MCP 生態對 Agent 工作流程更成熟。如果你在研究開源 Agent 替代方案,OpenClaw 值得看看。OpenAI 2025 年 10 月 DevDay 採納了 Anthropic 的 MCP 標準。Anthropic 創造的這個協定,現在被兩家平台上 70 多個 AI 用戶端共同使用。
同一個 prompt,兩種答案
「給我寫一篇 1500 字關於遠端辦公趨勢的部落格」
ChatGPT 45 秒左右給你一篇結構工整、略顯通用的文章。小標題規整、邏輯流暢、基本面都涵蓋了。讀起來像內容工廠的合格出品。
Claude 交出來的東西觀點更明確、細節更具體,聲音不像委員會拼湊出來的。耗時大概 60 秒。發出去前要改的地方更少。
「分析這份 40 頁 PDF,總結關鍵發現」
Claude 表現更好,因為它 200K 的上下文視窗能一口氣裝下整份文件,交叉引用不同章節時也不丟線。ChatGPT 能跑,但在跨頁引用的長文件上會開始掉上下文。
「幫我偵錯這個無限重渲染的 React 元件」
兩家都能定位到 useEffect 缺少依賴陣列。但 Claude 的回答還附帶解釋為什麼會進入重渲染循環,給出更宏觀的重構建議。ChatGPT 給修復更快,上下文更少。
「幫我規劃一個 SaaS 新創 6 個月的產品路線圖」
這時候用量限制的差距就咬人了。ChatGPT 讓你反覆迭代:起草、改寫、重構、重新產生,來回 30 次也不用擔心額度。Claude 的路線圖本身會更深——優先級更合理、時間線更現實、取捨分析更銳利——但你可能改三四輪額度就見底了。
「總結這份 80 頁的法律合約,標出高風險條款」
Claude 拉開距離。它的上下文視窗能裝下整份合約,把第 47 條和第 12 頁的賠償條款對上,不丟線索。ChatGPT 的 128K 處理大多數合約夠用,但非常長或引用密集的文件就會開始掉上下文。
誰該選哪個
選 ChatGPT Plus,如果:需要圖像生成、想用語音互動、更看重訊息體量而不是單條品質、每天要用多個 AI 功能(搜尋、圖像、語音、外掛)、想要最便宜的入門檔(8 美元的 Go)、需要最廣的外掛生態。
選 Claude Pro,如果:靠寫作吃飯、在意輸出品質、做正經編碼想用 Claude Code、經常處理長文件(200K 上下文)、推理深度比功能廣度重要、能接受更緊的用量限制、想要最好的 MCP 和 Agent 工作流程工具。
如果每月能掏 40 美元兩個都訂,那就是越來越多人的做法:Codex 拼速度 + Claude Code 拼品質、Claude 出初稿 + ChatGPT 做配圖,每個任務交給最擅長的工具。
這種混用路線正在成為重度用戶的常態。2026 年 3 月,「Claude vs ChatGPT」的搜尋量達到月均 11 萬次,同比翻了 11 倍。人們已經不只是好奇了,他們在挑日常主力工具,很多人挑到最後的答案是兩個都用。
如果你在圍繞這兩個工具搭自動化工作流程,問題就從「選哪個 AI」變成「哪個任務交給哪個 AI」。這才是 2026 年的真答案。
底線
ChatGPT 是瑞士軍刀。什麼都能做:文字、圖像、語音、搜尋、外掛、Agent。沒有哪一項是頂級的,但也沒有哪一項是壞的。想用一個訂閱把所有 AI 場景都湊合涵蓋,它是最穩的選擇。
Claude 是手術刀。能做的事情更少,但做的這幾件——寫作、編碼、推理、長上下文分析——ChatGPT 追不上。代價是真實的:更緊的限額、沒有圖像生成、語音還不成熟、功能面更窄。
如果非逼我 20 美元選一個,我按用途選。寫字的?Claude. 創意雜家?ChatGPT. 開發?從 Claude Code 開始,撞上限額再補 Codex。預算緊?ChatGPT 的 Go 檔 8 美元,是最便宜的能用的 AI 助手入口。
2026 年 4 月的最佳答案,和今年一貫的答案一樣讓人不舒服:看情況。
但現在你知道具體看哪些情況了。
FAQ
2026 年編碼 ChatGPT 和 Claude 哪個更好?
Claude Code 在盲測裡贏了 67%,SWE bench Verified 分數也更高(80.8% vs 約 80%)。但 Codex CLI 每個任務少燒 4 倍 tokens,20 美元檔上的用量限制也寬裕得多。比程式碼品質選 Claude,比成本和吞吐選 Codex。很多職業開發者兩個都用。
ChatGPT Plus 和 Claude Pro 每月給多少訊息?
ChatGPT Plus 用 GPT 5.3 每 3 小時約 160 條。Claude Pro 每 5 小時約 45 條,這個數字會隨長對話、附件、Claude Code 使用明顯下降。同價位下,ChatGPT 的原始訊息量顯著更多。
ChatGPT Go 的 8 美元檔值得買嗎?
Go 給你免費版 10 倍的額度、專案組織、32K 記憶視窗,每月 8 美元。但不含高級推理模型、Codex、Agent Mode、Deep Research 和 Tasks,還帶廣告。只想要一個更好的聊天機器人不碰生產力功能,它可以。
Claude 能像 ChatGPT 一樣產生圖像嗎?
不能。截至 2026 年 4 月,Claude 沒有原生圖像產生能力。ChatGPT 整合了 DALL-E 和原生圖像產生。圖像產生是工作流程一部分的話,只能選 ChatGPT。
AI 聊天機器人是應聲蟲嗎?
是的。史丹佛 2026 年 3 月發表在 Science 的研究測了 11 個主流模型,AI 肯定用戶的頻率比人類高 49%,即使用戶是錯的。這是產業普遍問題,不是某一家的。
2026 年寫作選哪個 AI 更好?
Claude 是專業寫作者的共識選擇。輸出聲音更自然、過渡更好、詞彙更豐富。任何聲音重要的場合選 Claude,批量結構化內容選 ChatGPT。
ChatGPT 和 Claude 兩個都訂嗎?
如果每月能出 40 美元,兩個都訂能拿到各自的最強面。寫作和複雜編碼交給 Claude,圖像、語音、快速查詢、大體量任務交給 ChatGPT。這是 2026 年大多數重度用戶的穩定解。
